Khai thác hiệu suất tốt hơn từ các hệ thống máy tính đã trở thành một vấn đề đầy thách thức vì nhiều lý do:
“Trong một thời gian, các nhà sản xuất tiếp tục thu nhỏ bóng bán dẫn và tăng tần số (mà không giảm điện áp) cho đến khoảng năm 2006 khi đạt đến một điểm khó có thể tiêu tan hiệu quả mật độ năng lượng kết quả, điều này đã ngăn Intel thúc đẩy kiến trúc Tejas và Jayhawk của họ”…”, nhưng vấn đề là đối với một tần số nhất định, có một điện áp tối thiểu cần thiết để bóng bán dẫn hoạt động, Đi thấp hơn thế và bóng bán dẫn không thể chuyển đổi ở tốc độ yêu cầu, cuối cùng gây ra sự cố hệ thống. “
1. Bức tường điện
Kể từ giữa những năm 2000, vật lý của các thiết bị nhỏ đã phát huy tác dụng. Điều này có nghĩa là chúng ta không còn có thể kiểm soát mật độ năng lượng trong khi tăng tần số và thu nhỏ bóng bán dẫn. Kết quả là, chúng tôi đã không thấy sự gia tăng đáng kể về tần số xung nhịp kể từ đó.
2. Bức tường song song cấp hướng dẫn
Rào cản hiệu suất này là do khó khăn ngày càng tăng trong việc tìm đủ tính song song trong một luồng lệnh duy nhất để giữ cho bộ xử lý lõi đơn hiệu suất cao bận rộn.
3. Bức tường ký ức
Điều này được gây ra bởi khoảng cách ngày càng tăng giữa bộ xử lý và tốc độ bộ nhớ. Điều này, trên thực tế, đẩy kích thước bộ nhớ cache lớn hơn để che giấu độ trễ của bộ nhớ. Điều này chỉ giúp ích trong phạm vi băng thông bộ nhớ không phải là rào cản về hiệu suất.
Hiệu suất bây giờ cần phải được trích xuất từ song song
Chúng tôi đã thấy CPU đa lõi trở thành tiêu chuẩn và các kiến trúc tiên tiến như thực thi lệnh siêu vô hướng và không theo thứ tựvà tiêu chuẩn trên cả những bộ xử lý cơ bản nhất.
Phần mềm và các công cụ khác như OpenCL đã được thành lập để giúp phát triển các hệ thống song song và phân tán đồng nhất.
Hệ thống máy tính không đồng nhất
Khi nhìn vào các thuật toán tăng tốc, đôi khi chỉ thực hiện song song mọi thứ là không đủ, chúng ta cũng cần gửi hướng dẫn đến đơn vị thực thi tối ưu nhất.
Đó là lý do tại sao các hệ thống có khả năng nhất thường liên quan đến môi trường điện toán nhiều mặt để khai thác khả năng của các thành phần khác nhau như CPU, GPU và FPGA.
CPU là gì?
CPU, hay Bộ xử lý trung tâm, là bộ xử lý được cài đặt ở trung tâm của máy tính. Nó nhận thông tin, xử lý và phân phối nó lên màn hình hoặc đến các thiết bị khác được kết nối với nó như card đồ họa, card âm thanh, máy in, máy quét, v.v.
Ưu điểm chính của CPU là chúng hỗ trợ bất kỳ khung lập trình nào: C / C ++, Scala, Java, Python, v.v. Đối với các khóa đào tạo học máy, CPU chủ yếu được sử dụng cho các mô hình đơn giản không mất nhiều thời gian để đào tạo. Nếu bạn đang chạy các mô hình và bộ dữ liệu lớn, thì tổng thời gian thực hiện cho đào tạo học máy sẽ bị cấm.
GPU là gì?
GPU là bộ xử lý chuyên dụng, được thiết kế chủ yếu để xử lý hình ảnh và video. Chúng dựa trên các đơn vị xử lý đơn giản hơn so với CPU, nhưng chúng có thể lưu trữ số lượng lõi lớn hơn nhiều, khiến chúng trở nên lý tưởng cho các ứng dụng trong đó dữ liệu cần được xử lý song song như pixel của hình ảnh hoặc video. GPU được lập trình bằng các ngôn ngữ như CUDA và OpenCL và do đó không linh hoạt so với CPU.
Vì các lõi trở nên chuyên dụng hơn, nên việc phụ thuộc vào việc trích xuất song song tự động trở nên khó khăn. Kết quả là, đã có một sự thay đổi cho các nhà phát triển để xác định rõ ràng tính song song cấp luồng tại thời điểm mã hóa để tận dụng các môi trường không đồng nhất đa lõi.
Khi mô hình này đã lan truyền, rõ ràng là một mô hình tiêu chuẩn cho lập trình song song đa nền tảng là cần thiết. Đây là lúc OpenCL phát huy tác dụng.
Phương pháp tiếp cận lập trình song song
OpenCL cho phép lập trình viên chỉ định tính song song sẽ được sử dụng bởi hệ thống máy tính khi thực thi thuật toán. Cách tiếp cận này cung cấp một số lợi thế trong thế giới ngày nay.
Chưa kể rằng biết thuật toán của bạn tốt nhất, có nghĩa là có thể quyết định nơi song song có thể được sử dụng. OpenCL sau đó sẽ cho phép bạn thể hiện ngầm hoặc rõ ràng sự song song đó để hệ thống hiểu. Nó ở mức cao hơn so với song song cấp lệnh và ngày nay thường hiệu quả hơn so với tính song song mà trình biên dịch hoặc bộ xử lý có thể tự trích xuất.
Các loại song song
Theo truyền thống, có hai cách tiếp cận để lập trình song song, song song dữ liệu và song song nhiệm vụ. FPGA cũng cho phép khai thác tính song song của đường ống. Hầu hết các ứng dụng sẽ sử dụng kết hợp các kỹ thuật khác nhau.
Song song dữ liệu
Còn được gọi là thu thập phân tán, trong đó dữ liệu đầu vào được chia thành các tập hợp con sao cho mỗi tập con được gửi đến các tài nguyên song song và sau khi xử lý xong, kết quả được kết hợp.
Song song nhiệm vụ
Còn được gọi là chia-và-chinh phục. Với cách tiếp cận chia để chinh phục, các vấn đề được chia thành các vấn đề phụ chạy tốt trên các tài nguyên tính toán song song có sẵn.
Song song đường ống
Đề cập đến việc xây dựng một đường ống các nhiệm vụ, mỗi nhiệm vụ có mối quan hệ giữa nhà sản xuất và người tiêu dùng. Một luồng dữ liệu sau đó sẽ lấp đầy đường ống và mỗi tác vụ sẽ làm việc trên một phần dữ liệu khác nhau khi dữ liệu đi qua. OpenCL có các cấu trúc cho phép bạn mô hình hóa dữ liệu và song song tác vụ và Intel FPGA SDK cho OpenCL có khả năng khai thác song song đường ống trong FPGA.
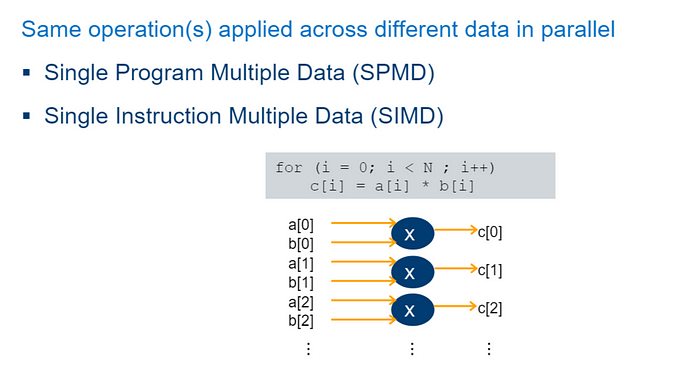
Song song dữ liệu — Ví dụ
Dưới đây là một ví dụ điển hình về phương pháp thu thập phân tán. Trong code, chúng ta thấy chúng ta đang thực hiện phép nhân vectơ với vòng lặp for lặp qua tất cả các phần tử của mảng và thực hiện phép nhân. Vì các nhân N độc lập với dữ liệu, có nghĩa là không có phép nhân nào phụ thuộc vào kết quả của các phép nhân khác, tất cả các phép nhân này đều có thể được thực hiện song song. Đây là tình huống lý tưởng cho song song dữ liệu.
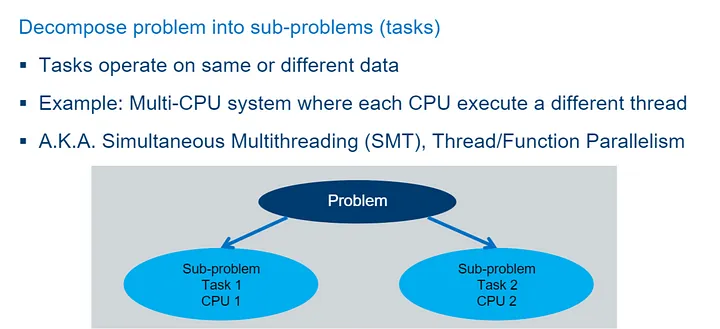
Song song nhiệm vụ — Ví dụ
Với cách tiếp cận chia để chinh phục, còn được gọi là song song nhiệm vụ hoặc song song luồng, các vấn đề được chia thành các vấn đề phụ. Mỗi vấn đề phụ được thực hiện song song trên các phần cứng khác nhau. Một ví dụ điển hình sẽ là một hệ thống đa CPU trong đó mỗi CPU thực thi một luồng khác nhau.
Pipeline Parallelism — Ví dụ
Song song đường ống tạo ra một chuỗi các nhiệm vụ có mối quan hệ giữa nhà sản xuất và người tiêu dùng với nhau. Một luồng dữ liệu đường ống được nhập vào quy trình tác vụ. Mỗi tác vụ sau đó hoạt động trên một phần dữ liệu khác nhau trong luồng và chuyển nó sang nhiệm vụ tiếp theo khi nó kết thúc. Bằng cách này, nhiều phần dữ liệu đang được vận hành bởi các tác vụ khác nhau ở mỗi bước thời gian. Một ví dụ về điều này sẽ là thực hiện Chuyển đổi Fourier nhanh trên dữ liệu âm thanh, thực hiện bộ lọc tần số và sau đó chuyển đổi dữ liệu trở lại miền thời gian bằng FFT nghịch đảo.
Chia sẻ & đồng bộ hóa dữ liệu
Khi thực hiện song song các tác vụ, việc chia sẻ và đồng bộ dữ liệu giữa các tác vụ luôn là một thách thức vì sự phụ thuộc dữ liệu phải được biết và giải quyết. Điều này có thể dẫn đến ý nghĩa thiết kế phần cứng. Các tác vụ sẽ chỉ yêu cầu đồng bộ hóa nếu chúng có sự phụ thuộc dữ liệu vào nhau. Ví dụ về điều này là mối quan hệ người tiêu dùng của nhà sản xuất trong đó kết quả của một nhiệm vụ là cần thiết cho nhiệm vụ tiếp theo hoặc tình huống mà kết quả trung gian được chia sẻ bởi nhiều nhiệm vụ. Các phương pháp truyền thống để đồng bộ hóa bao gồm các rào cản và khóa.
Rào cản: Dừng nhiệm vụ cho đến khi tất cả các nhiệm vụ đã đạt đến rào cản đó.
Khóa: Cung cấp các giới hạn cho các tài nguyên mà chúng được áp dụng. Mô hình trừu tượng của OpenCL cung cấp nhiều cơ chế để chia sẻ và đồng bộ hóa dữ liệu.
Mô hình bộ nhớ dùng chung
Khi cùng một dữ liệu cần thiết cho nhiều tác vụ, cách tiếp cận đơn giản nhất là triển khai mô hình bộ nhớ dùng chung trong đó tất cả các tác vụ đều thấy cùng một bộ nhớ. Bộ nhớ có thể được sử dụng để giao tiếp giữa các tác vụ và có thể được bảo vệ bởi semaphores hoặc mutexes để đảm bảo dữ liệu mạch lạc và sẽ không bị hỏng. Mỗi tác vụ cũng có thể có bộ nhớ cục bộ riêng trong mô hình này. Ưu điểm của mô hình này là đơn giản để thực hiện và các lập trình viên không bắt buộc phải quản lý chuyển động dữ liệu. Hạn chế là vì nhiều tác vụ truy cập vào cùng một bộ nhớ, nó có thể làm phức tạp và làm chậm kết nối. Vì vậy, nó không thể mở rộng. Hầu hết các nền tảng đa lõi đều hỗ trợ mô hình này. Và OpenCL cũng hỗ trợ điều này.
Mô hình truyền tin nhắn
Một cách tiếp cận khác để đồng bộ hóa dữ liệu là mô hình truyền thông điệp. Với mô hình này, nhiều tác vụ đồng thời trên cùng một thiết bị hoặc bất kỳ số lượng thiết bị nào giao tiếp rõ ràng. Dữ liệu được theo dõi riêng biệt bởi các nhiệm vụ và chuyển giao được thực hiện khi được yêu cầu. Dữ liệu được gửi bởi một tác vụ phải được khớp với dữ liệu nhận được bởi một tác vụ khác. Lợi ích chính của mô hình này là nó có thể mở rộng vì giao tiếp chỉ được thực hiện trên cơ sở cần thiết. Hạn chế là các lập trình viên cần quản lý thông tin liên lạc một cách rõ ràng nên việc phát triển khó khăn hơn và thường việc gửi và nhận dữ liệu đòi hỏi một thư viện thói quen cụ thể gây khó khăn cho việc phát triển các ứng dụng di động.
Tổng quan về OpenCL
Đặc điểm OpenCL
OpenCL ‘cung cấp các cơ chế cho tính toán song song bằng cách sử dụng cả song song dựa trên tác vụ và dựa trên dữ liệu. Tiêu chuẩn cung cấp các API được sử dụng để xác định và kiểm soát các nền tảng thiết bị từ máy chủ. Nó cũng bao gồm một phiên bản của ngôn ngữ lập trình C, để viết hạt nhân hoặc các hàm thực thi trên các thiết bị OpenCL. OpenCL có thể được ánh xạ đến các kiến trúc khác nhau và có thể trích xuất hiệu suất cao từ mỗi kiến trúc. Nó độc lập với các nhà cung cấp và thiết bị.
Thuộc tính OpenCL
Như đã nêu trước đó, OpenCL hỗ trợ cả song song dữ liệu và song song tác vụ. Nhưng cả hai cần phải được tuyên bố rõ ràng. Tính song song dữ liệu đạt được khi chúng tôi khởi chạy rõ ràng các tác vụ song song dữ liệu trên không gian làm việc. Mỗi tác vụ này về cơ bản là các luồng song song, là các trường hợp của hạt nhân tính toán. Tính song song nhiệm vụ đạt được theo cách do máy chủ kiểm soát thông qua việc sử dụng hàng đợi và sự kiện. Hàng đợi chỉ định danh sách các tác vụ và sự kiện được sử dụng cho mục đích đồng bộ hóa.
Hai mặt của tiêu chuẩn OpenCL
Tiêu chuẩn OpenCL được chia thành hai phần: ngôn ngữ phía thiết bị và ngôn ngữ phía máy chủ hoặc API. Về phía thiết bị, ngôn ngữ này thường được gọi là Kernel Code hoặc OpenCL C. Các hạt nhân được ánh xạ tới một loạt các máy gia tốc với phần cứng khác nhau. Thông thường điều này được sử dụng cho các tác vụ tính toán chuyên sâu về dữ liệu song song. Về phía máy chủ, API OpenCL hỗ trợ quản lý hiệu quả các chương trình đồng thời phức tạp với chi phí thấp. Phần này thường chạy trên bộ vi xử lý thông thường như bộ xử lý x86. Khi được sử dụng cùng nhau, các thuật toán song song hiệu quả có thể được thực hiện.
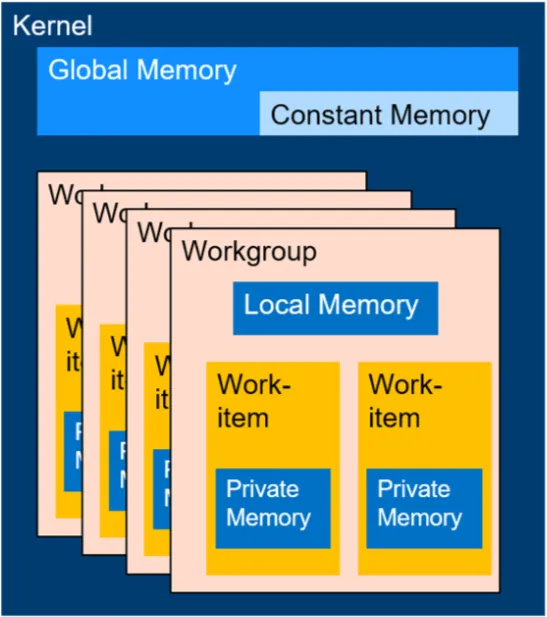
Mô hình bộ nhớ OpenCL
Mô hình bộ nhớ OpenCL mô hình hóa một số loại bộ nhớ khác nhau với các đặc điểm khác nhau. Các biến và con trỏ trong kernel đủ điều kiện với loại bộ nhớ mà chúng nên được triển khai bên trong. Bộ nhớ toàn cầu hiển thị cho mọi luồng và có độ trễ cao nhất. Bộ nhớ cục bộ hiển thị cho các luồng trong cùng một nhóm làm việc. Bộ nhớ cục bộ có thể được sử dụng làm bộ nhớ đệm để tăng hiệu suất khi so sánh với bộ nhớ toàn cầu. Bộ nhớ riêng chỉ hiển thị với một luồng duy nhất và hoạt động tốt như một bàn di chuột nhỏ. Bộ nhớ máy chủ hiển thị với CPU máy chủ và có thể được chia sẻ với thiết bị trong các trường hợp duy nhất.
OpenCL bằng ví dụ
Hãy xem xét một thuật toán độc lập dữ liệu. Ở đây chúng ta có một hàm gọi là increment với ba đối số: mảng để tăng, một giá trị để tăng theo và số lượng các phần tử trong mảng. Khi chúng ta gọi hàm, hàm lặp qua toàn bộ mảng phần tử và thực hiện gia số cần thiết. Trên kiến trúc CPU, thông thường tất cả các hoạt động thêm N sẽ được thực hiện tuần tự trong thời gian.
Hạt nhân
Trong OpenCL, chúng ta có thể song song hóa hàm gia tăng bằng cách tạo một hạt nhân tương ứng. Một kernel có thể được thực thi bởi nhiều work-items hoặc thread nếu nó được viết dưới dạng kernel NDRange. Điều này sẽ khai thác tính song song dữ liệu. Cùng một hạt nhân chính xác sẽ được thực thi trên mỗi phần dữ liệu đầu vào. Ngoài ra, khi được biên dịch cho FPGA, hạt nhân có thể cung cấp song song đường ống.
Bây giờ, chúng ta hãy xem xét một số ví dụ.
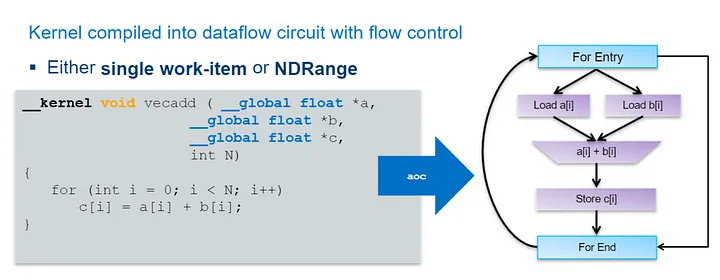
OpenCL theo ví dụ – Single Work-Item Kernel
Ở đây chúng ta lấy hàm C mà chúng ta đã kiểm tra trước đây và triển khai nó như một hạt nhân. Không có nhiều thay đổi, ngoại trừ việc chúng tôi đã thêm một số từ khóa – kernel và global. Lưu ý rằng hàm kernel đứng trước hạt nhân từ khóa. Cũng lưu ý rằng hạt nhân phải trả về loại void. Cuối cùng, hãy lưu ý rằng các đối số con trỏ của kernel phải đủ điều kiện với loại bộ nhớ bạn muốn chúng được triển khai, trong trường hợp này làbộ nhớ chung.
Hạt nhân có thể là mục công việc đơn lẻ hoặc NDRange. Hạt nhân này là một hạt nhân mục công việc duy nhất vì nó lặp qua toàn bộ mảng dữ liệu sẽ được gửi đến nó cùng một lúc dưới dạng một mục công việc duy nhất.
Một lợi thế của việc mã hóa các hạt nhân mục công việc đơn lẻ là các phụ thuộc có thể được mã hóa vào hạt nhân và được triển khai dưới dạng các vòng phản hồi với định tuyến rất dễ dàng.
Hạt nhân NDRange
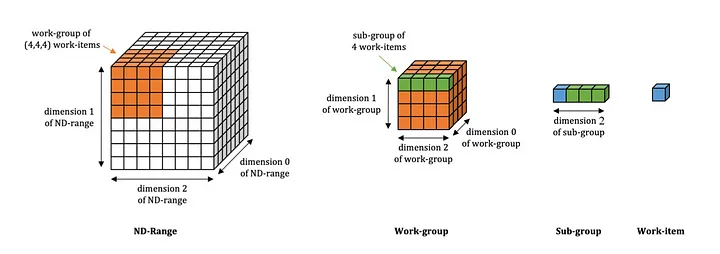
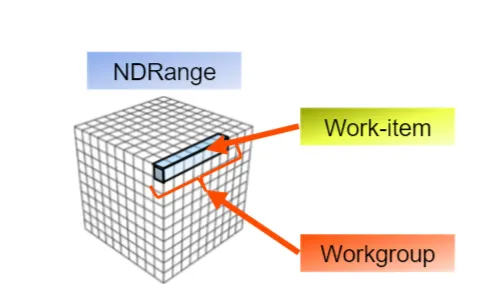
Hạt nhân NDRange là các hạt nhân OpenCL™ truyền thống hơn khởi chạy nhiều luồng song song dữ liệu. Điều này được thực hiện trong một chương trình nhiều dữ liệu, hoặc SPMD, thời trang. Hạt nhân tuyên bố rõ ràng tính song song của dữ liệu.
Trong thuật ngữ OpenCL, mỗi luồng được gọi là work-item. Mỗi hạng mục công việc được nhóm lại thành một nhóm làm việc và các nhóm làm việc cùng nhau tạo thành toàn bộ NDRange. Các mục công việc trong một nhóm làm việc có thể đồng bộ hóa và chia sẻ dữ liệu và mỗi nhóm làm việc độc lập với các nhóm làm việc khác.
OpenCL by Example — NDRange Kernel
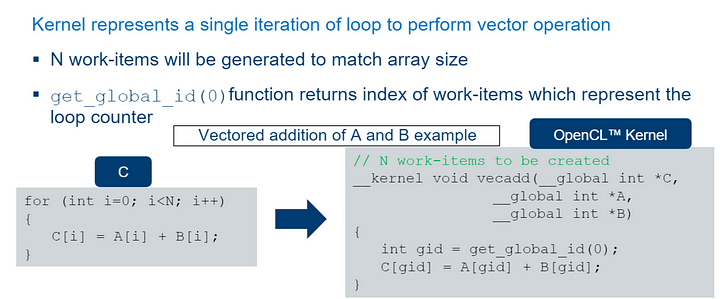
Đây là vector ví dụ của chúng tôi thêm mã một lần nữa, bây giờ được triển khai như một hạt nhân NDRange.
Ở đây chúng ta có ba đối số đều là mảng số nguyên. A và B là đầu vào và C là đầu ra. Phần thân của hạt nhân đại diện cho một lần lặp duy nhất của một vòng lặp sẽ thực hiện cùng một vectơ thêm.
Khi chúng ta khởi chạy kernel, chúng ta làm như vậy với N số lượng work-items phù hợp với kích thước mảng. Vì vậy, trong dòng đầu tiên của phần thân của kernel, chúng ta sử dụng get_global_id(0) để lấy vị trí của work-item trên các số N. Điều này giống như bộ đếm chỉ mục trong một vòng lặp. Việc tính toán được thực hiện trong dòng thứ hai của thân hạt nhân. Chúng ta lấy các phần tử thích hợp của A và B được lập chỉ mục bởi gid và cộng chúng lại với nhau, sau đó lưu trữ kết quả trong phần tử c được lập chỉ mục bởi gid.
Vì vậy, mỗi lần thực thi kernel chỉ thực hiện một lần thêm trong vector add của chúng ta.
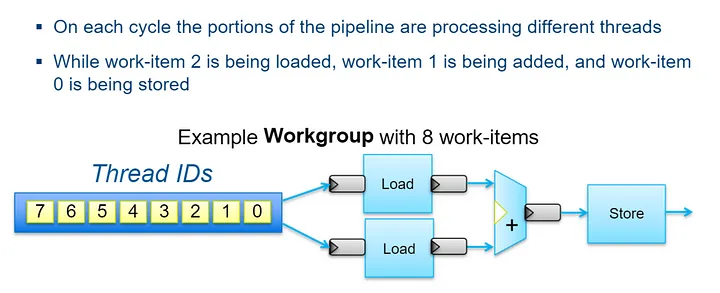
Song song đường ống của hạt nhân NDRange
Các hạt nhân được triển khai trong FPGA của Intel® cũng sẽ ngầm tận dụng tính song song của đường ống. Dưới đây là một ví dụ về cách pipeline đó sẽ hoạt động với vector add kernel mà chúng ta vừa thấy. Khi các phần dữ liệu đầu vào cho mỗi luồng bắt đầu chảy vào, đường ống được lấp đầy, cho đến khi cuối cùng mỗi phần cứng đang làm việc trên tính toán đang làm việc trên một phần dữ liệu khác nhau cùng một lúc.
Tính song song của pipeline này được triển khai cho dù bạn code một work-item hay NDRange kernel. Ưu điểm của một hạt nhân mục công việc duy nhất là các phụ thuộc có thể dễ dàng được mã hóa và tích hợp vào đường ống.
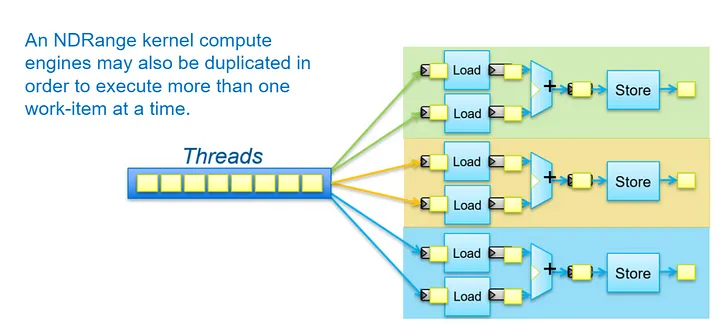
Song song hóa dữ liệu của hạt nhân NDRange
Khi nhân NDRange được triển khai, các đơn vị tính toán hoặc thành phần tính toán của hạt nhân có thể được sao chép tùy chọn bằng cách sử dụng các thuộc tính. Điều này có nghĩa là nhiều hơn một mục công việc sẽ được thực thi cùng một lúc, cung cấp dữ liệu song song.
Lưu ý: Bài viết này là tóm tắt những gì chúng tôi đã học được từ khóa học Intel ‘Giới thiệu về Điện toán song song với OpenCL’